Новые алгоритмы значительно ускоряют процессы машинного обучения в децентрализованных сетях.

Результаты опубликованы в материалах конференции NeurIPS 2024. Современное машинное обучение зачастую базируется на обучении моделей на обширных объемах данных, что требует распределенных вычислений. Федеративное обучение (Federated Learning, FL) представляет собой подход, который позволяет обучать модели на децентрализованных данных, хранящихся на множестве устройств (смартфоны, медицинские приборы и так далее), без необходимости прямого обмена этими данными.
Ключевая проблема федеративного обучения заключается в высокой коммуникационной сложности. А именно, передача данных и вычисление градиентов на их основе (векторов, описывающих направление изменения параметров модели) становятся проблемами, которые замедляют весь процесс обучения. Коммуникационная сложность возникает из-за огромного объема передач данных по сети, необходимых для достижения заданной точности решения.
Обычно для решения этой проблемы применяется стохастический градиентный спуск. Он основан на использовании неполной информации для вычисления градиента, выбирая данные случайным образом. Такие методы делятся на методы с возвращением и без возвращения. При выборе с возвращением один и тот же набор данных может быть выбран несколько раз, тогда как при выборе без возвращения каждый набор данных выбирается только один раз.
В недавней статье, представленной на конференции NeurIPS 2024, авторы предлагают новые подходы. Они разработали четыре новых алгоритма, которые объединяют сжатие градиентов с методом случайной перестановки и локальными вычислениями.
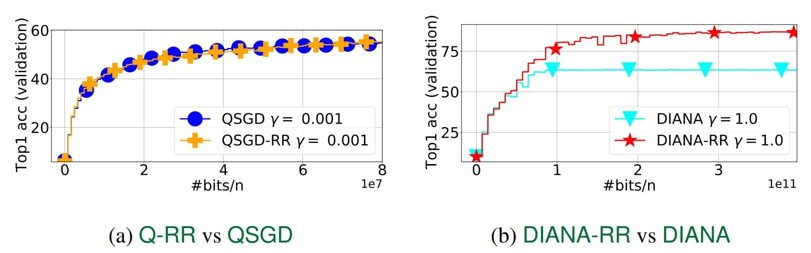
Первый из новых алгоритмов получил название Q-RR (Quantized Random Reshuffling). Это самый простой подход, который сочетает сжатие градиентов и метод перестановки. К сожалению, теоретический анализ показал, что этот метод не демонстрирует преимуществ по сравнению с традиционными методами сжатия градиентов.
Второй метод, предложенный учеными и названный DIANA-RR, является модификацией первого. Они улучшили предыдущий подход, добавив снижение дополнительной дисперсии, возникшей из-за сжатия градиентов. В результате им удалось создать алгоритм с лучшей скоростью сходимости, чем существующие аналоги, основанные на выборке с возвращением.
Для лучшей адаптации к задачам федеративного обучения ученые расширили алгоритмы Q-RR и DIANA-RR, добавив локальные вычислительные шаги. В результате появились еще два новых метода, получивших названия Q-NASTYA и DIANA-NASTYA. Эти методы используют разные размеры шагов для локальных и глобальных обновлений. Однако как DIANA-NASTYA, так и DIANA-RR предназначены для уменьшения дополнительной дисперсии, вызванной сжатием градиентов.
Авторы исследования провели теоретический анализ и три численных эксперимента, подтвердивших эффективность предложенных алгоритмов. Алгоритмы DIANA-RR и DIANA-NASTYA значительно превосходят существующие методы по скорости сходимости, особенно при высокой степени сжатия градиентов и в условиях, требующих высокой точности.
Для моделирования в первых двух экспериментах авторы использовали решение бинарной задачи классификации (определение принадлежности объектов к одному из двух классов) методом логистической регрессии с регуляризацией. В этих экспериментах они сравнивали локальные и нелокальные методы.
Результаты, полученные в численных экспериментах, полностью соответствовали выведенной теории.
В третьем эксперименте авторы применили нелокальные методы для распределенного машинного обучения глубокой нейронной сети, и в нем новые методы также продемонстрировали свои преимущества по сравнению с традиционными подходами.
«Многие существующие работы в области федеративного обучения рассматривают методы стохастического градиентного спуска с возвращением. Однако недавно было показано как теоретически, так и практически, что методы, основанные на выборке без возвращения, такие как метод случайной перестановки, работают лучше», — отметил Абдурахмон Садиев, научный сотрудник лаборатории численных методов прикладной структурной оптимизации ФПМИ МФТИ.
Разработанные алгоритмы представляют собой значимый вклад в область федеративного обучения, позволяя значительно ускорить процесс обучения больших моделей при ограниченных коммуникационных ресурсах. Это открывает новые перспективы для применения машинного обучения в различных областях, где важна защита конфиденциальности данных. Будущие исследования будут сосредоточены на оптимизации алгоритмов и их адаптации к более сложным задачам федеративного обучения.