Нові алгоритми пришвидшують машинне навчання в децентралізованих мережах.

Результати опубліковані в матеріалах конференції NeurIPS 2024. Сучасне машинне навчання часто спирається на навчання моделей на величезних обсягах даних, що вимагає розподілених обчислень. Федеративне навчання (Federated Learning, FL) — це підхід, який дозволяє навчати моделі на децентралізованих даних, що зберігаються на безлічі пристроїв (смартфони, медичні прилади тощо), без прямого обміну цими даними.
Ключова проблема федеративного навчання полягає у високій комунікаційній складності. А саме, передача даних і обчислення градієнтів на їх основі (векторів, що характеризують напрямок зміни параметрів моделі) стає проблемою, яка сповільнює весь процес навчання. Комунікаційна складність полягає в величезній кількості передач даних по мережі, необхідних для досягнення заданої точності рішення.
Зазвичай для вирішення цієї проблеми використовують стохастичний градієнтний спуск. Він ґрунтується на використанні неповної інформації для обчислення градієнта, вибираючи дані для цього випадковим чином. Такі методи діляться на методи з поверненням і без повернення. При виборі з поверненням один і той же набір даних може бути обраний кілька разів, а при виборі без повернення кожен набір даних вибирається лише один раз.
У новій статті, представленій на конференції NeurIPS 2024, автори пропонують нові підходи. Вони розробили чотири нових алгоритми, які поєднують стиснення градієнтів з методом випадкової перестановки та локальними обчисленнями.
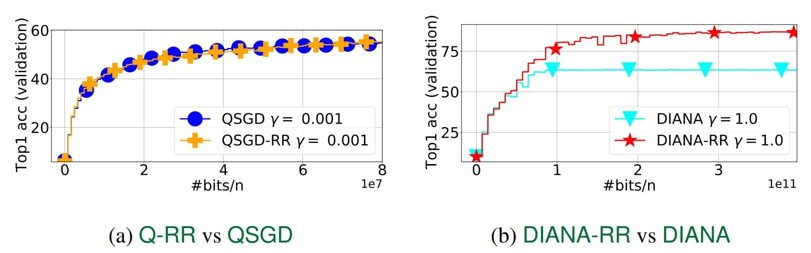
Перший новий алгоритм вони назвали Q-RR (Quantized Random Reshuffling). Це найпростіший підхід, що поєднує стиснення градієнтів і метод перестановки. На жаль, теоретичний аналіз показав, що цей метод не демонструє переваги перед традиційними методами стиснення градієнтів.
Другий запропонований вченими метод, названий ними DIANA-RR, є модифікацією першого. Вони покращили попередній підхід, додавши зменшення додаткової дисперсії, яка виникла через стиснення градієнтів. В результаті їм вдалося отримати алгоритм, який має кращу швидкість збіжності, ніж існуючі аналоги, засновані на вибірці з поверненням.
Для кращої адаптації до задач федеративного навчання вчені розширили алгоритми Q-RR і DIANA-RR, додавши локальні обчислювальні етапи. Так вони отримали ще два нових методи, які назвали Q-NASTYA і DIANA-NASTYA. Ці методи використовують різні розміри кроків для локальних і глобальних оновлень. Проте і DIANA-NASTYA, і DIANA-RR призначені для зменшення додаткової дисперсії, що вноситься стисненням градієнтів.
Автори дослідження провели теоретичний аналіз і три числові експерименти, які підтвердили ефективність запропонованих алгоритмів. Алгоритми DIANA-RR і DIANA-NASTYA значно перевершують за швидкістю збіжності існуючі методи, особливо при високій ступені стиснення градієнтів і в умовах, коли потрібна висока точність.
Для моделювання в перших двох експериментах автори використовували рішення бінарної проблеми класифікації (перевірка належності об'єктів до одного з двох класів) методом логістичної регресії з регуляризацією. У перших двох експериментах вони порівнювали локальні та нелокальні методи.
Виявилося, що результати, спостережувані в числових експериментах, ідеально відповідали виведеній теорії.
У третьому експерименті автори використовували нелокальні методи для розподіленого машинного навчання глибокої нейронної мережі, і в ньому нові методи також продемонстрували свою перевагу над традиційними підходами.
«Багато існуючих робіт у сфері федеративного навчання розглядають методи стохастичного градієнтного спуску з поверненням. Однак нещодавно вдалося показати як теоретично, так і практично, що методи, засновані на вибірці без повернення, наприклад, метод випадкової перестановки, працюють краще», — розповів Абдурахмон Садієв, науковий співробітник лабораторії числових методів прикладної структурної оптимізації ФПМІ МФТИ.
Розроблені алгоритми є важливим внеском у сферу федеративного навчання, дозволяючи значно прискорити процес навчання великих моделей при обмежених комунікаційних ресурсах. Це відкриває нові можливості для застосування машинного навчання в різних сферах, де важлива захист конфіденційності даних. Подальші дослідження будуть спрямовані на оптимізацію алгоритмів і їх адаптацію до більш складних задач федеративного навчання.