New algorithms are accelerating machine learning in decentralized networks.

The results have been published in the proceedings of the NeurIPS 2024 conference. Modern machine learning often relies on training models on vast amounts of data, which necessitates distributed computing. Federated Learning (FL) is an approach that enables model training on decentralized data stored across numerous devices (such as smartphones and medical devices) without directly sharing this data.
A key challenge of federated learning lies in its high communication complexity. Specifically, the transmission of data and the computation of gradients based on this data (vectors that indicate the direction of change in model parameters) becomes an issue that slows down the entire training process. The communication complexity arises from the enormous number of data transfers over the network required to achieve a specified accuracy in the solution.
Typically, stochastic gradient descent is employed to address this issue. It relies on utilizing incomplete information to compute the gradient by randomly selecting the data used for this purpose. These methods are categorized into sampling with replacement and without replacement. In the case of sampling with replacement, the same dataset can be selected multiple times, while in sampling without replacement, each dataset is selected only once.
In a recent paper presented at the NeurIPS 2024 conference, the authors propose new approaches. They developed four novel algorithms that combine gradient compression with random reshuffling and local computations.
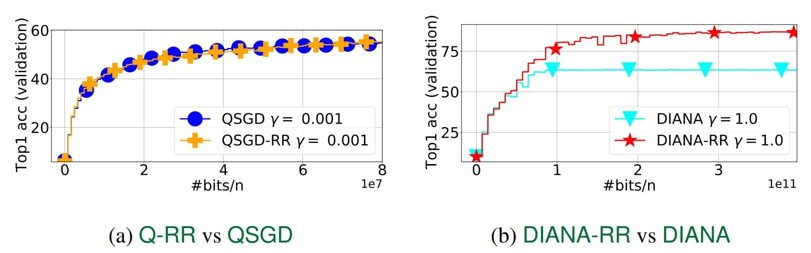
The first new algorithm is named Q-RR (Quantized Random Reshuffling). This is the most straightforward approach that merges gradient compression with the reshuffling method. Unfortunately, theoretical analysis revealed that this method does not demonstrate advantages over traditional gradient compression techniques.
The second method proposed by the researchers, called DIANA-RR, is a modification of the first. They enhanced the previous approach by adding a reduction of additional variance that arose from gradient compression. As a result, they achieved an algorithm that exhibits better convergence speed compared to existing sampling-with-replacement analogs.
To better adapt to the challenges of federated learning, the researchers expanded the Q-RR and DIANA-RR algorithms by introducing local computational steps. This led to the creation of two additional new methods, named Q-NASTYA and DIANA-NASTYA. These methods utilize different step sizes for local and global updates. However, both DIANA-NASTYA and DIANA-RR aim to reduce the additional variance introduced by gradient compression.
The authors of the study conducted a theoretical analysis and three numerical experiments that confirmed the effectiveness of the proposed algorithms. The DIANA-RR and DIANA-NASTYA algorithms significantly outperform existing methods in terms of convergence speed, especially when a high degree of gradient compression is applied and high accuracy is required.
For modeling in the first two experiments, the authors utilized a binary classification problem solution (testing object membership in one of two classes) using logistic regression with regularization. In these initial experiments, they compared local and non-local methods.
It turned out that the results observed in the numerical experiments perfectly aligned with the derived theory.
In the third experiment, the authors employed non-local methods for distributed deep neural network training, where the new methods also demonstrated their superiority over traditional approaches.
“Many existing works in the field of federated learning consider stochastic gradient descent methods with replacement. However, it has recently been shown both theoretically and practically that methods based on sampling without replacement, such as the random reshuffling method, perform better,” said Abdurakhmon Sadiev, a researcher at the Laboratory of Numerical Methods for Applied Structural Optimization at the Faculty of Physics, MIPT.
The developed algorithms represent a significant contribution to the field of federated learning, allowing for substantial acceleration of the training process for large models under limited communication resources. This opens up new opportunities for applying machine learning in various domains where data privacy is crucial. Future research will focus on optimizing the algorithms and adapting them to more complex federated learning tasks.